
[Review] LSTM-CNN for Human Activity Recognition
![[Review] LSTM-CNN for Human Activity Recognition](/content/images/size/w960/2025/09/Blue-and-Gray-Modern-Thesis-Defense-Presentation.png)
Source reviewed: Xia, Huang, & Wang (2020), “LSTM-CNN Architecture for Human Activity Recognition,” IEEE Access 8, DOI: 10.1109/ACCESS.2020.2982225. Licensed under CC BY 4.0 (you may reuse with attribution).
This paper proposes a compact LSTM-CNN architecture for sensor-based Human Activity Recognition (HAR) that first models temporal dynamics with stacked LSTMs and then learns spatial/channel patterns via 1-D convolutions. By replacing fully connected (FC) layers with Global Average Pooling (GAP) and adding Batch Normalization (BN), the model cuts parameters substantially while maintaining or improving accuracy across UCI-HAR, WISDM, and OPPORTUNITY benchmarks (≈96%, 96%, and 93% overall accuracy, respectively). The authors also present ablations on network design and hyper-parameters (optimizers, filter counts, batch size).
Why This Paper Matters (Context & Positioning)
Traditional HAR pipelines often depend on hand-crafted features (e.g., statistical descriptors, Relief-F, SFFS) plus classical classifiers (SVM, kNN, RF), which can limit generalization and require domain expertise. The deep-learning turn in HAR shifts to end-to-end feature learning from raw multi-axis inertial signals. This study contributes by showing that a temporal-first (LSTM) → spatial-next (CNN) stack—coupled with GAP+BN—can be both accurate and lightweight, a useful property for mobile/embedded applications.
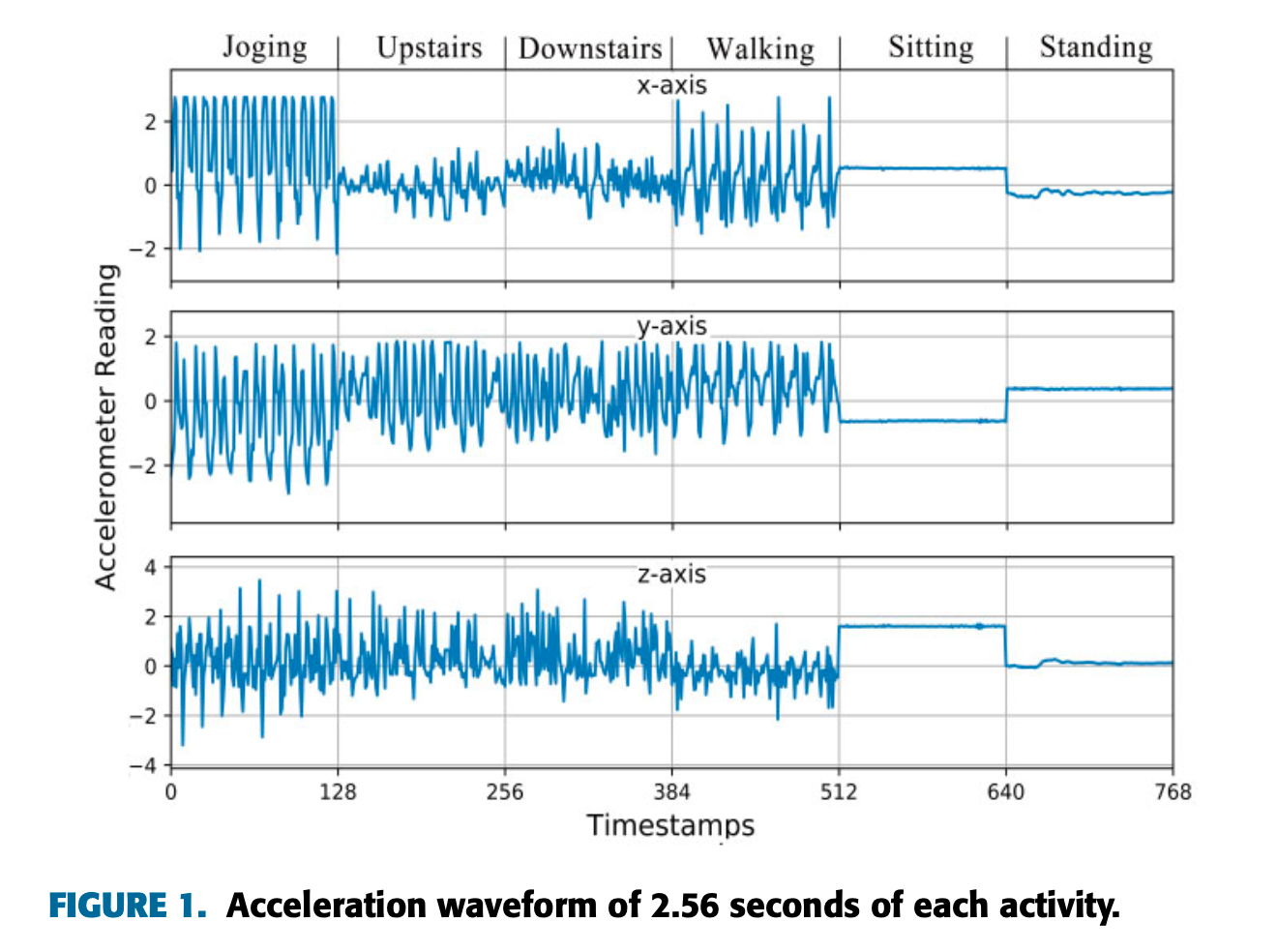
Datasets, Preprocessing & Segmentation
- Datasets:
- UCI-HAR: 30 subjects, 6 activities, smartphone IMU @ 50 Hz.
- WISDM: 36 subjects, 6 activities, smartphone accelerometer @ 20 Hz; class imbalance (e.g., Walking ≈38.6%, Standing ≈4.4%).
- OPPORTUNITY: rich on-body multi-modal setup (up to 113 channels), 17 gesture/locomotion classes including a Null class, @ 30 Hz.
- Missing data: filled via linear interpolation.
- Normalization: per-channel min-max scaling to [0, 1].
- Segmentation: fixed windows with 50% overlap: 128 samples for UCI-HAR/WISDM; 24 samples for OPPORTUNITY (short gestures). Choice is empirical/adaptive.
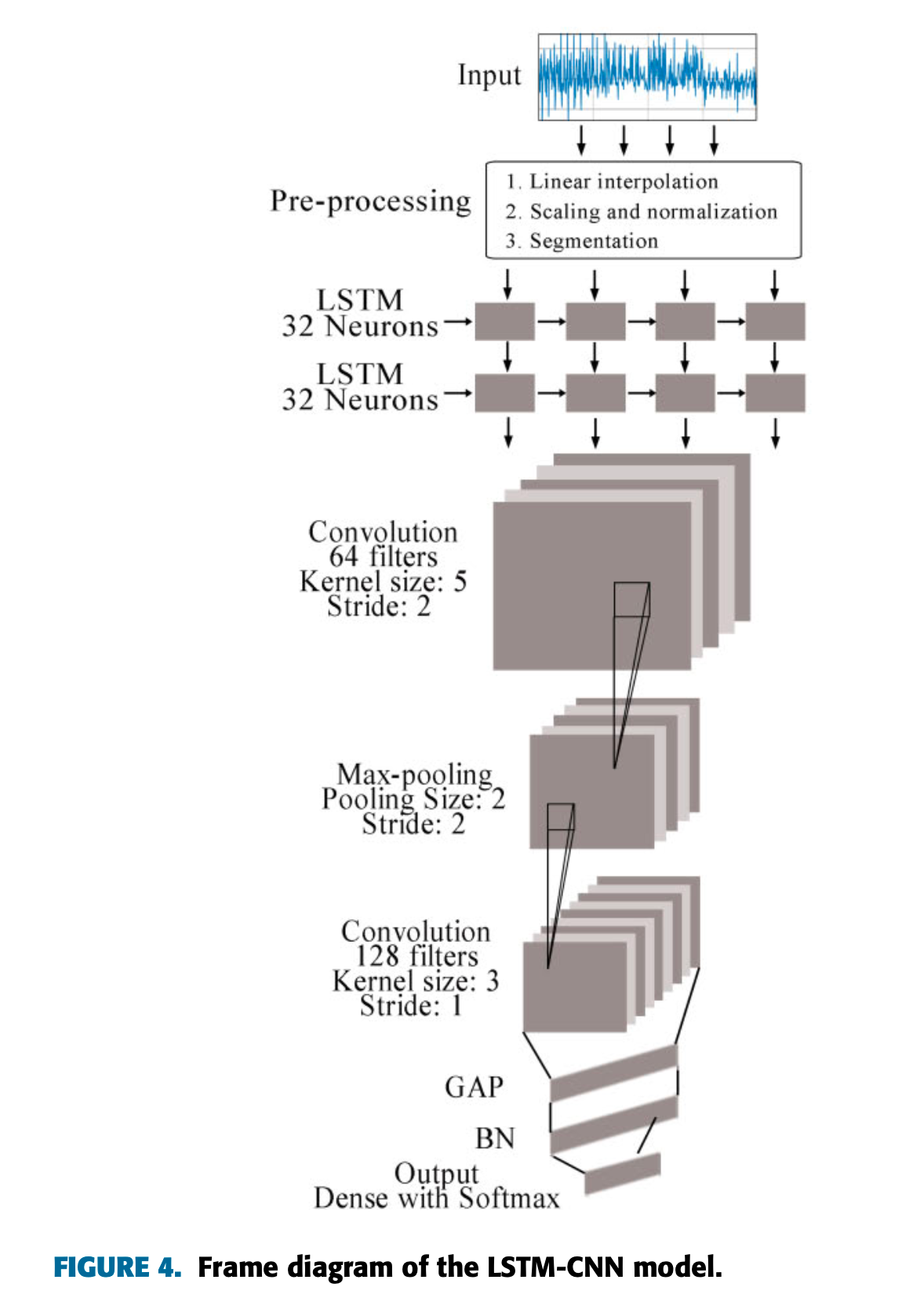
Model Architecture
Eight-layer pipeline (temporal → spatial → global pooling/normalization → classifier):
- Two LSTM layers (total 64 units; described also as 32 memory cells per layer) to capture sequential dependencies. Output reshaped to fit CNN input.
- Conv block:
- Conv1: 64 filters, kernel 1×5, stride 2, ReLU.
- Max-Pooling (downsampling, noise suppression).
- Conv2: 128 filters, kernel 1×3, stride 1, ReLU.
- GAP (replaces large FC layers to reduce params and improve robustness).
- BN (stabilizes distributions post-GAP; accelerates convergence).
- Output head: small FC (feature merging) + Softmax for class probabilities.
Design rationale:
- LSTMs mitigate RNN vanishing-gradient issues for long sequences, enabling multi-scale temporal dynamics learning before convolutional filtering.
- GAP dramatically shrinks parameter count versus FC layers (e.g., classic CNN FC layers can add tens of millions of weights), improving deployability. BN then offsets the slower convergence that GAP-only variants might exhibit.
Training Setup
- Frameworks: Keras (TensorFlow backend).
- Optimizer: Adam chosen after comparing SGD/Adagrad/Adadelta/RMSprop; Adam showed the best, most stable convergence in their setting.
- Hyper-params: batch size 192, 200 epochs, LR 0.001, shuffled batches; supervised cross-entropy training with backprop through the full stack.
Evaluation Protocol & Metrics
- Subject-wise splits to reduce leakage:
- UCI-HAR: 22 subjects train / 8 test.
- WISDM: 30 train / 6 test.
- OPPORTUNITY: standard challenge split (Subject 1 + parts of 2,3 train; ADL4–5 of 2,3 test).
- Class imbalance: Report F1-score in addition to accuracy to avoid inflated results from majority classes. Confusion matrices are presented for each dataset.
Results
- Overall accuracy (test sets):
- UCI-HAR: ~95.8%; misclassifications mainly between Sitting vs Standing.
- WISDM: ~95.8% despite imbalance.
- OPPORTUNITY: ~92.6% overall; ~87.6% when excluding the Null class.
- Comparisons to deep baselines: The proposed LSTM-CNN outperforms Yang et al.’s CNN and DeepConvLSTM (Ordóñez & Roggen) across datasets by ~3% on average; the gain reaches ~7% on OPPORTUNITY.
Ablations & Design Insights
- Replacing FC with GAP:
- A classic CNN with FC (Model A) achieves F1 ≈ 91.9% on UCI-HAR but uses >500k parameters and trains ~1681 ms/epoch.
- With GAP instead of FC (Model B), parameters drop to ~27k (≈94% reduction) with similar F1 and faster training. Adding BN (Model C) speeds convergence and improves F1 further.
- Adding LSTMs (temporal→spatial):
- Feeding sequences through LSTM layers before CNN (Model D and final LSTM-CNN) boosts F1 up to ~95.8%, confirming the value of explicitly modeling temporal context; training per-epoch time increases due to LSTM’s sequential dependencies.
- Optimizer choice: Adam provides the most stable/accurate training among tested options.
- Filter count: Increasing Conv2 filters raises accuracy (F1 up to ~96.4% at 192 filters) but inflates parameters 70%+, indicating a compute-accuracy trade-off.
- Batch size: Accuracy peaks around batch=192 in their experiments.
Strengths
- Compact yet accurate: Smart use of GAP+BN for parameter efficiency without sacrificing performance.
- Temporal-first design: Stacked LSTMs effectively capture motion dynamics before spatial filtering.
- Cross-dataset validation: Evaluated on three widely used benchmarks with subject-wise splits, supporting generalization claims.
- Transparent ablations: Clear evidence on how each architectural decision affects accuracy, convergence, and parameter count.
Limitations & Considerations
- Latency/throughput: LSTMs increase per-epoch time; for on-device inference, 1-D CNNs or TCNs might be faster if accuracy remains acceptable. The paper does not quantify real-time inference latency on mobile hardware.
- Sensor modalities: While OPPORTUNITY shows multi-modal robustness, the core architecture and experiments emphasize inertial signals; integrating barometer or temperature would require channel-wise adaptation and possibly attention mechanisms.
- Window choice: Window sizes are empirically chosen; tasks with highly variable action lengths may benefit from adaptive segmentation or sequence models with attention.
Practical Takeaways (for your projects)
- Preprocessing: Use min-max scaling and 50% overlap windows; start with 2–3 s windows at your sensor rate; fill NaNs via linear interpolation.
- Backbone: Try LSTM(32) → LSTM(32) → Conv(64, k=5, s=2) → MaxPool → Conv(128, k=3) → GAP → BN → small FC → Softmax as a strong baseline.
- Hyper-params: Adam, LR=1e-3, batch≈192, epochs≈200 are sensible starting points; then tune Conv2 filters (trade accuracy vs. model size).
- Metrics: Report F1 (macro/weighted) and confusion matrices whenever classes are imbalanced (e.g., Idle/Null vs active states).
Reproducibility & Deployment Notes
- Frameworks: Keras/TensorFlow are used; PyTorch equivalents are straightforward.
- Parameter budgeting: Favor GAP to avoid large FCs; if you later add attention or residuals, keep the head lightweight for embedded targets.
- Generalization: Maintain subject-wise splits and consider leave-one-subject-out validation for stronger robustness checks.
Suggested BibTeX (with Attribution)
@article{Xia2020LSTMCNNHAR,
title = {LSTM-CNN Architecture for Human Activity Recognition},
author = {Kun Xia and Jianguang Huang and Hanyu Wang},
journal = {IEEE Access},
volume = {8},
pages = {56855--56866},
year = {2020},
doi = {10.1109/ACCESS.2020.2982225},
note = {Licensed under CC BY 4.0}
}
(Re-use permitted with attribution under Creative Commons Attribution 4.0.)
Reference to the Reviewed Article
Xia, K., Huang, J., & Wang, H. (2020). LSTM-CNN Architecture for Human Activity Recognition. IEEE Access, 8, 56855–56866. https://doi.org/10.1109/ACCESS.2020.2982225 (CC BY 4.0).